

This demo contains models trained on the DeepLoc Dataset. Select a model to load from the drop down box below and click on an image in the carosel to see the live results. To learn more about the network architectures and the approach employed, please see the How Does it Work section below.
Note: No pre-computation is performed for these images. They are treated as a fresh upload with every click. Inference time might vary depending on the current server load and number of users.
Vlocnet++

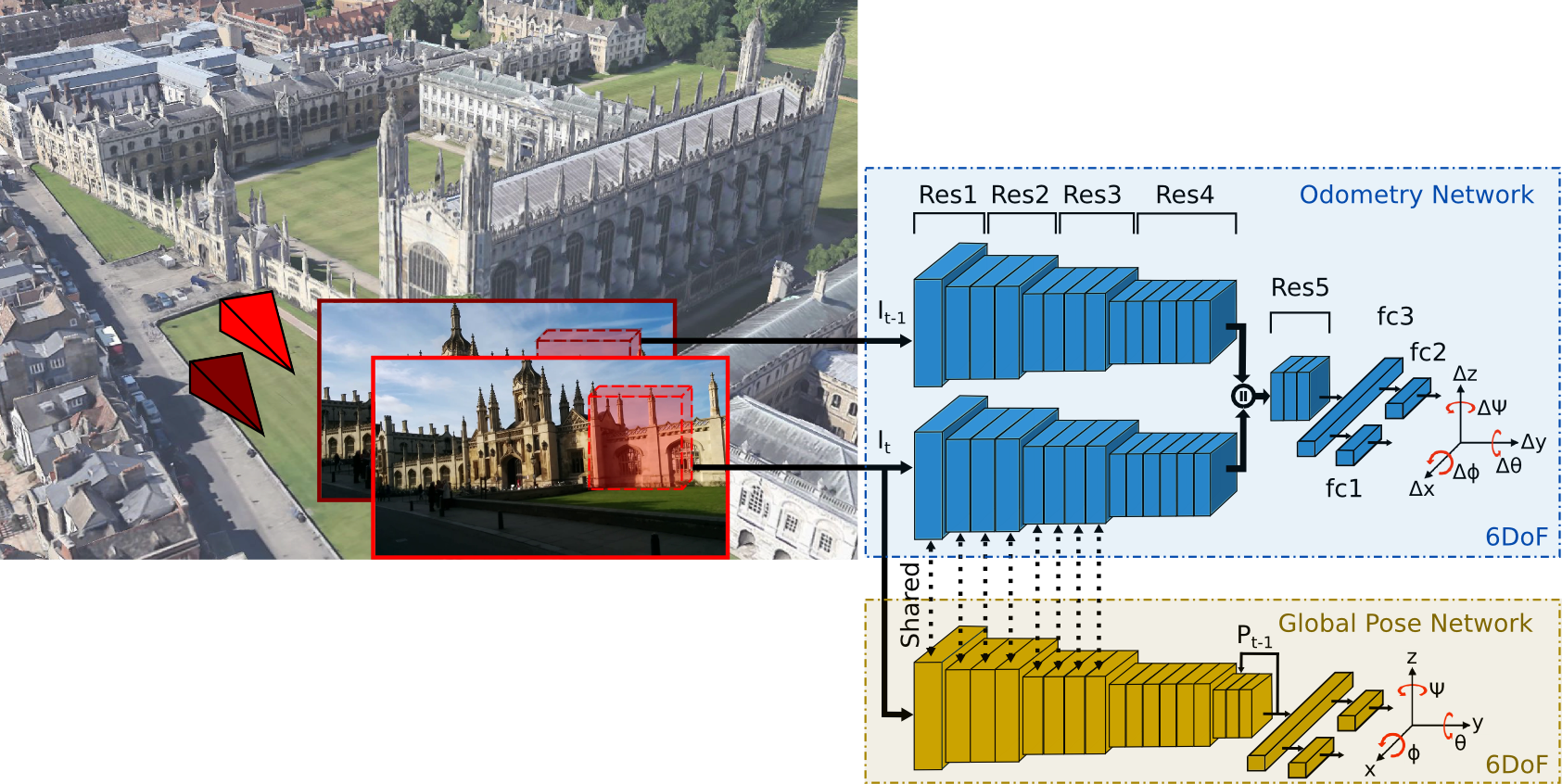
VLocNet is a new convolutional neural network architecture for 6-DoF global pose regression and odometry estimation from consecutive monocular images. Our multitask model incorporates hard parameter sharing, thus being compact and enabling real-time inference on a consumer grade GPU. We propose a novel Geometric Consistency Loss function that utilizes auxiliary learning to leverage relative pose information during training, thereby constraining the search space to obtain consistent pose estimates.
We evaluate our proposed VLocNet on the challenging Microsoft 7-Scenes benchmark and the Cambridge Landmarks dataset, and show that even our single task model exceeds the performance of state-of-the-art deep architectures for global localization, while achieving competitive performance for visual odometry estimation. Furthermore, we present extensive experimental evaluations utilizing our proposed Geometric Consistency Loss that show the effectiveness of auxiliary learning and demonstrate that our model is the first deep learning technique to be on par with, and in some cases outperform state-of-the-art SIFT-based approaches.
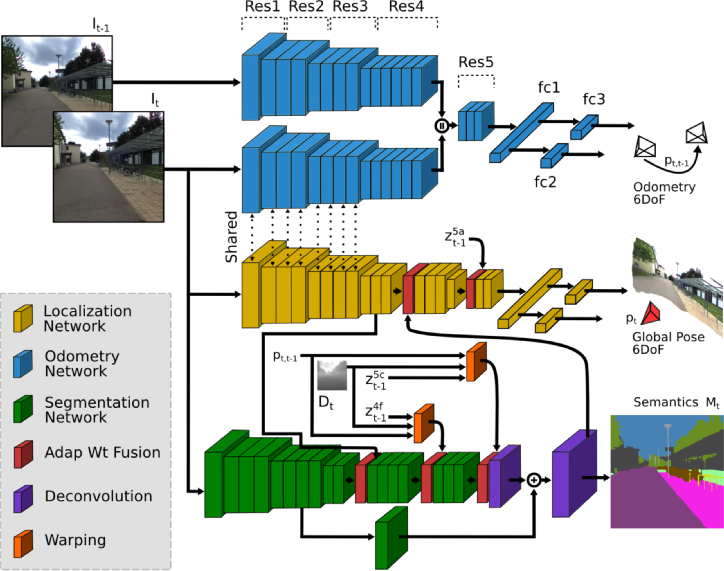
The VlocNet++ model jointly estimates the global pose, odometry and semantic segmentation from consecutive monocular images. We build upon the recently introduced VLocNet architecture and propose key improvements to encode geometric and structural constraints into the pose regression network, namely by incorporating information from the previous timesteps to accumulate motion specific information and by adaptively fusing semantic features based on the activations in the region using our proposed adaptive fusion scheme. We also propose a novel self-supervised aggregation technique based on differential warping that improves the segmentation accuracy and reduces the training time by half. Our architecture consists of four CNN streams; a global pose regression stream, a semantic segmentation stream and a Siamese-type double stream for visual odometry estimation.
Given a pair of consecutive monocular images \(I_{t-1}, I_{t} \in \mathbb{R}^{\rho}\), the pose regression stream in our network predicts the global pose \(\mathbf{p}_{t}=[\mathbf{x}_{t}, \mathbf{q}_{t}]\) for image \(I_{t}\), where \(\mathbf{x} \in \mathbb{R}^3\) denotes the translation and \(\mathbf{q} \in \mathbb{R}^4\) denotes the rotation in quaternion representation, while the semantic stream predicts a pixel-wise segmentation mask \(M_t\) mapping each pixel \(u\) to one of the \(\mathit{C}\) semantic classes, and the odometry stream predicts the relative motion \(\mathbf{p}_{t, t-1}=[\mathbf{x}_{t, t-1}, \mathbf{q}_{t, t-1}]\) between consecutive input frames. \(z_{t-1}\) denotes the feature maps from the previous timestep. Extensive evaluations on the Microsoft 7-Scenes dataset and our newly introduced DeepLoc dataset demonstrate that our approach sets the state-of-the-art, while being more than 60.5% faster and simultaneously performing multiple tasks. For more information on the approach, please refer to the arXiv submission.

We introduce a large-scale urban outdoor localization dataset collected around the university campus using our autonomous robot platform equipped with a ZED stereo camera mounted facing the front of the robot. RGB and depth images were captured at a resolution of 1280 x 720 pixels and at 20 Hz. The dataset is currently comprised of one scene spanning an area of 110 x 130 m, that the robot traverses multiple times with different driving patterns. We plan to add more scenes to this dataset as this project progresses. We use our LiDAR-based SLAM system with sub-centimeter and sub-degree accuracy to compute the pose labels that we provide as groundtruth. Poses in our dataset are approximately spaced by 0.5 m which is twice as dense as other relocalization datasets.
Furthermore, for each image we provide pixel-wise semantic segmentation annotations for ten categories: Background, Sky, Road, Sidewalk, Grass, Vegetation, Building, Poles & Fences, Dynamic and Void. To the best of our knowledge, this is the first dataset for which images tagged with localization poses and semantic segmentation labels are provided for an entire scene with multiple loops. We divided the dataset into a train and test splits such that the train set comprises seven loops with alternating driving styles amounting to 2737 images, while the test set comprises three loops with a total of 1173 images. Our dataset also contains global GPS/INS data and LiDAR measurements.
This dataset can be very challenging for vision based applications such as global localization, camera relocalization, semantic segmentation, visual odometry and loop closure detection, as it contains substantial lighting, weather changes, repeating structures, reflective and transparent glass buildings. The 3D model built by our SLAM system can be visualized below.
The data is provided for non-commercial use only. By downloading the data, you accept the license agreement which can be downloaded here. If you report results based on the DeepLoc dataset, please consider citing the papers mentioned in the Publications section below.

We introduce the challenging DeepLocCross dataset which we captured using our robotic platform equipped with a ZED stereo camera mounted facing the front of the robot. We collected the data around a highly dynamic road segment spanning an area of 158x90 m2 which contains a tram line as well as multiple pedestrian crossings and road intersections. Similar to the DeepLoc dataset, the DeepLocCross dataset contains RGB-D stereo images captured at 1280 x 720 pixels at a rate of 20 Hz. The ground-truth pose labels are generated using the LiDAR-based SLAM system from here. In addition to the 6-DoF localization poses of the robot, the dataset additionally contains tracked detections of the observable dynamic objects. Each tracked object is identified using a unique track ID, spatial coordinates, velocity and orientation angle. Furthermore, as the dataset contains multiple pedestrian crossings, we provide labels at each intersection indicating its safety for crossing.
This dataset consists of seven training sequences with a total of 2264 images, and three testing sequences with a total of 930 images. The dynamic nature of the surrounding environment at which the dataset was captured renders the tasks of localization and visual odometry estimation extremely challenging due to the varying weather conditions, presence of shadows and motion blur caused by the movement of the robot platform. Furthermore, the presence of multiple dynamic objects often results in partial and full occlusions to the informative regions of the image. Moreover, the presence of repeated structures render the pose estimation task more challenging. Overall this dataset covers a wide range of perception related tasks such as loop closure detection, semantic segmentation, visual odometry estimation, global localization, scene flow estimation and behavior prediction.
The data is provided for non-commercial use only. By downloading the data, you accept the license agreement which can be downloaded here. If you report results based on the DeepLocCross dataset, please consider citing the papers mentioned in the Publications section below.
VLocNet++ achieves state-of-the-art performance on the Microsoft 7-Scenes dataset. We show qualitative results by vizualizing the predicted poses with reference to the groundtruth. The predicted poses are shown in red and the groundtruth poses are shown in yellow. Note that we only use the 3D model for visualization and our approach does not require it for localization. Click on the "In Tab" button to load the scene in the embedded viewer and the "New Tab" button top open the viewer in a new window. You can use the mouse pointer to rotate the scene, the mouse wheel to zoom into the scene, shift+click to pan through the scene or ctrl+click to titlt the scene.
VLocNet++ achieves state-of-the-art performance on the challenging DeepLoc dataset which was collected outdoors in the university campus. The predicted poses are shown in red and the groundtruth poses are shown in yellow. Note that we only use the 3D model for visualization and our approach does not require it for localization. Click on the "In Tab" button to load the scene in the embedded viewer and the "New Tab" button top open the viewer in a new window. You can use the mouse pointer to rotate the scene, the mouse wheel to zoom into the scene, shift+click to pan through the scene or ctrl+click to titlt the scene.
Noha Radwan,
Abhinav Valada,
Wolfram Burgard
VLocNet++: Deep Multitask Learning for Semantic Visual Localization and Odometry
IEEE Robotics and Automation Letters (RA-L), 3(4):4407-4414, 2018.
Abhinav Valada,
Noha Radwan,
Wolfram Burgard
Deep Auxiliary Learning for Visual Localization and Odometry
Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, Australia, 2018.


